
Back in 2020, when Meta first introduced Retrieval-Augmented Generation (RAG), it was a clever hack to overcome a limitation: language models could only handle around 4,000 tokens of context.
Imagine trying to fit the entire knowledge of your company’s documentation, FAQs or research papers into just a few pages of memory. It was impossible. So the idea was born:
➡️ instead of forcing the model to “remember” everything, let it retrieve relevant information from an external database whenever needed,
and then use that information to generate grounded, factual responses.
That was the seed.
⚙️ How it started
Early RAG systems were simple.
You had three core components:
- A vector database (like Pinecone, FAISS or Milvus) that stored chunks of documents as embeddings.
- An embedding model that converted both queries and documents into numerical vectors.
- A retriever + generator pipeline in which the retriever pulled similar chunks and the generator (an LLM) crafted the final answer.
It worked surprisingly well for FAQs and closed-domain tasks. But as adoption grew, the limitations became clear.
Chunking was naive as it splits documents by size, not meaning.
Embedding models missed domain-specific synonyms.
And the retriever often returned text that looked semantically close but was contextually irrelevant. For instance: ask about “how to enable 2FA in Gmail,” and you’d get passages about “multi-factor auth in Microsoft Teams.”
Looks similar, but completely misses the intent.
That’s when the field matured. Teams realised RAG isn’t about fetching similar text; it’s about fetching the right text.
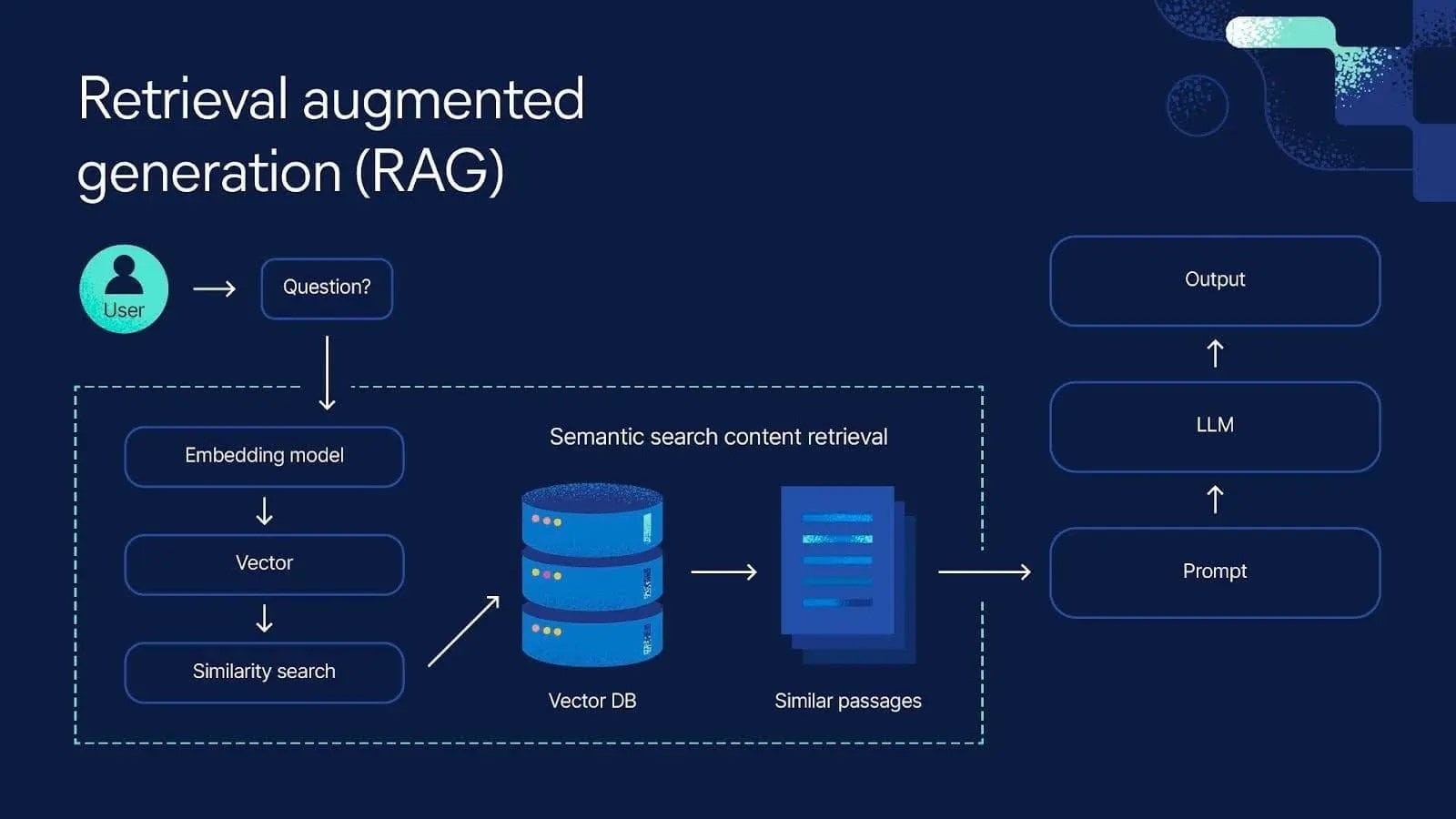
🔍 How it’s evolving
Today, RAG has become a whole discipline which includes part of retrieval science and part of reasoning engineering.
Modern RAG systems use a hybrid retrieval architecture:
- Semantic Search with embeddings for meaning-based similarity
- BM25 for exact keyword and lexical matching
- Rerankers like Cohere Rerank 3.5 to reorder results by contextual relevance
- Fine-tuned embeddings for specific domains (finance, legal, biotech etc.)
Documents are semantically chunked, not just split by token length.
The result? Far fewer hallucinations, much higher factual precision, and a huge leap in retrieval accuracy.
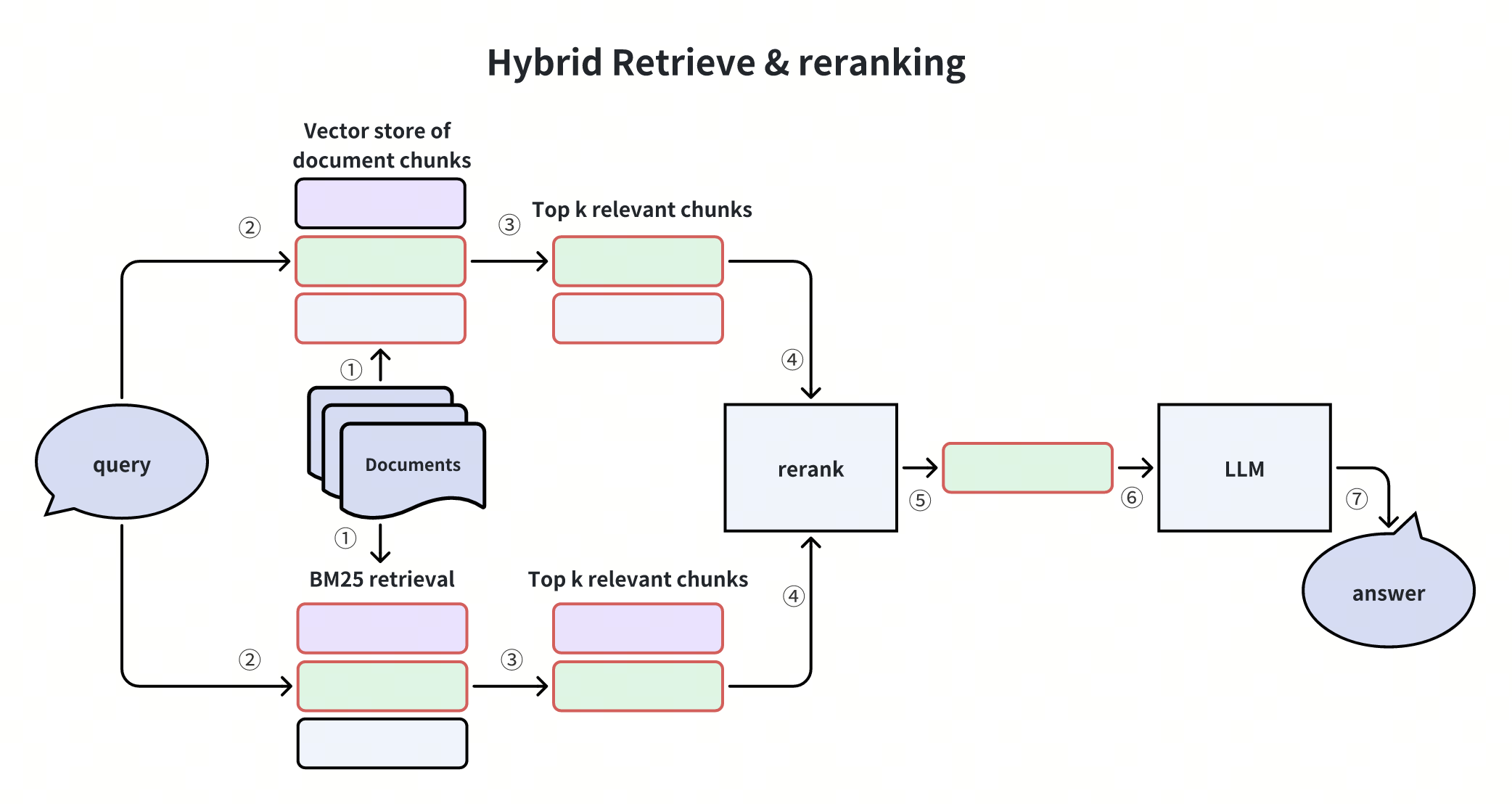
Some teams even go beyond:
- HyDE (Hypothetical Document Embeddings) imagines an ideal answer, embeds that, then retrieves supporting documents, a retrieval system powered by imagination.
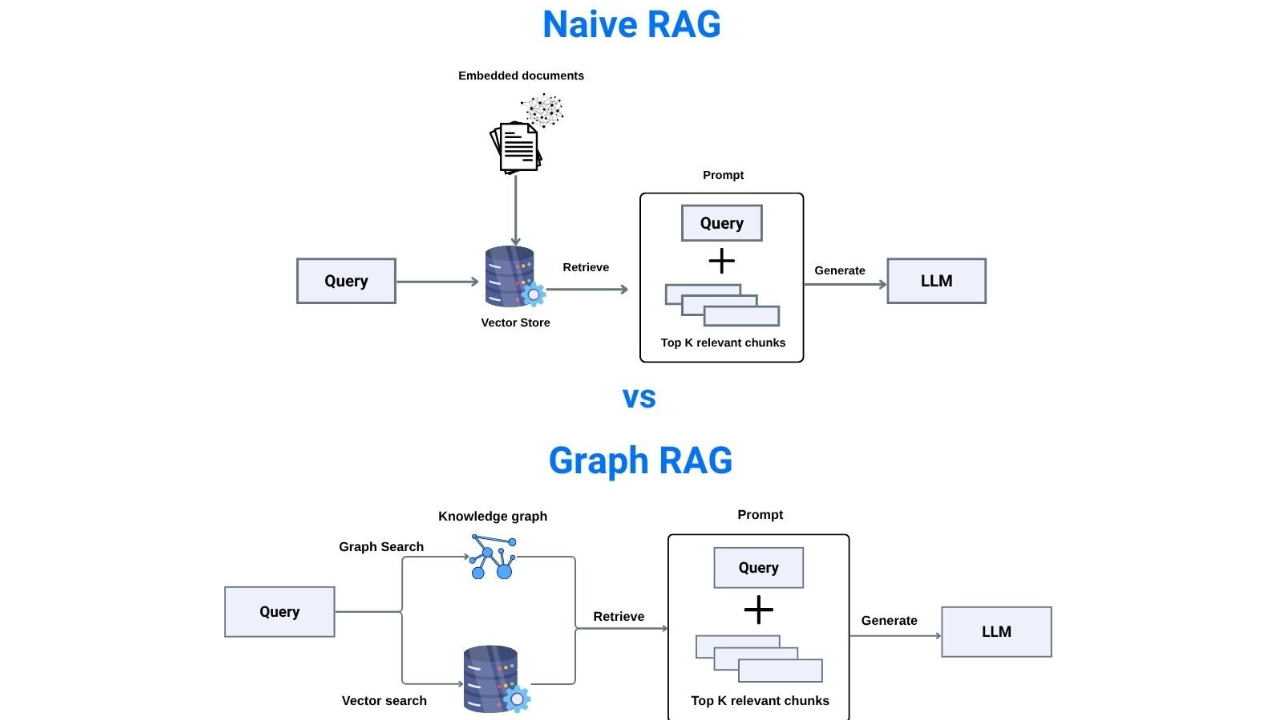
- Graph RAG represents data as nodes and edges, enabling multi-hop reasoning, perfect for cause-effect or relational questions.
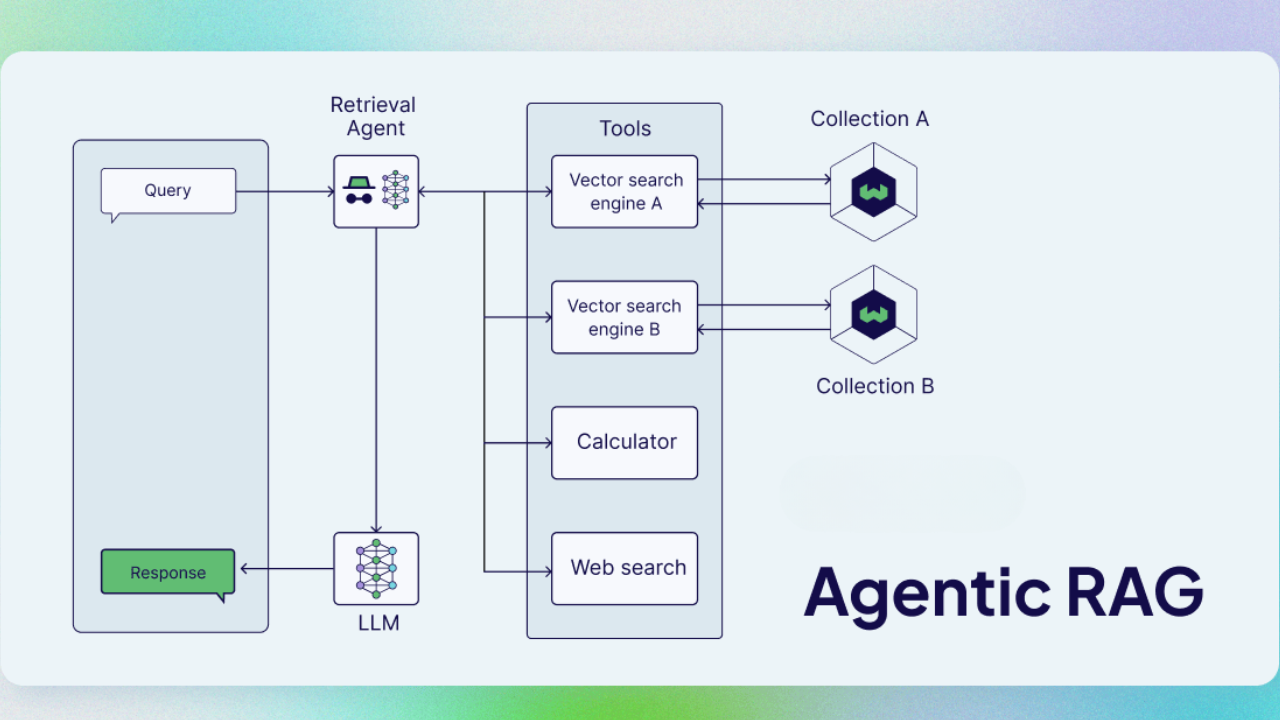
- Agentic RAG breaks complex queries into subtasks, retrieves iteratively, verifies and self-corrects. It’s like RAG meets reasoning agents.
So, 2023 was about building RAGs that worked, 2025 is about making them think.
💡 How to measure if your RAG “actually works”
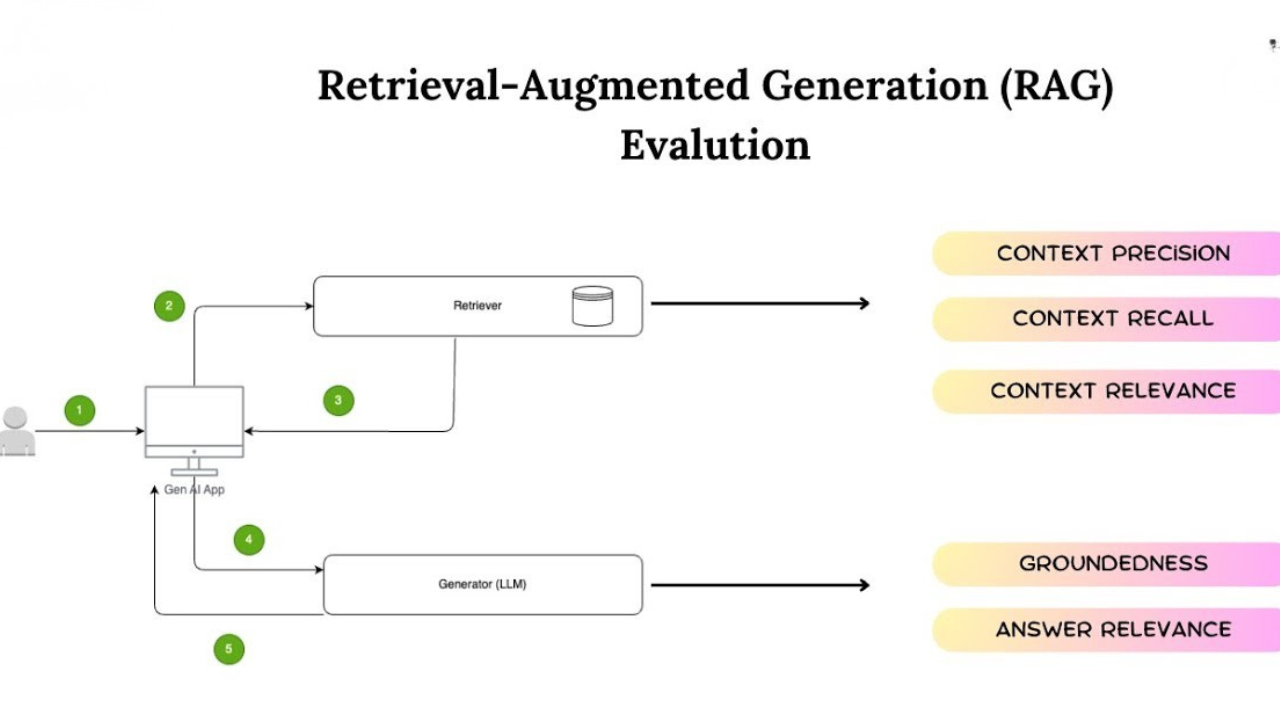
Most people can build a RAG pipeline. However, few can measure it properly and without evaluation, you’re flying blind. A strong evaluation framework separates retrieval from generation because you can’t fix what you can’t isolate.
Retrieval Metrics:
- Context Recall → Did we retrieve all necessary information?
- Context Precision → Of what we retrieved, how much was actually useful?
- MRR & NDCG → How well did we rank the relevant chunks?
Generation Metrics:
- Faithfulness → Are generated answers factually grounded in the retrieved context?
- Relevancy → Does the response directly address the query?
- Correctness → Does it match the verified ground truth?
Moreover, tools like Ragas automate these metrics and hybrid evaluation pipelines now make it affordable. So, Instead of evaluating every case with an expensive model like GPT-5, you start with fast, deterministic metrics, then use Conformal Prediction to measure confidence.
Only the uncertain cases are escalated to a heavyweight LLM.
The result?
→ GPT-5-level evaluation quality while spending on just 7% of the dataset.
→ A 15× cost reduction and finally, continuous RAG evaluation that’s practical.
🧩 The subtle engineering layer nobody talks about
Many RAG systems fail not because of model quality, but prompt design.
Chain-of-thought prompts can increase latency and even worsen hallucinations.
In production, prompts should be treated like code:
clean, minimal, single-responsibility.
Additionally, metadata also plays a silent but powerful role. Instead of throwing the entire corpus at the retriever, teams now partition data based on structured metadata by team, category or recency, ensuring context windows are focused and balanced and for static knowledge bases, some teams even move to Cache-Augmented Generation (CAG) where the entire context is preloaded and cached, eliminating retrieval altogether for known, unchanging data.
🔭 The future: From context to cognition
The future of RAG isn’t bigger context windows, it’s smarter retrieval.
Meta’s new models can handle 10M tokens (enough to fit 10,000 internal wiki pages in one call), but raw size alone doesn’t create understanding.
The next wave of breakthroughs is about:
- Context compression —> distilling retrieved docs to only the essence before feeding them to the LLM.
- Instruction-tuned embedding models —> where you tell the embedder what to care about (“retrieve legal arguments” vs. “retrieve technical solutions”).
- Filtered semantic search —> applying metadata filters like date, author, or domain for fresh, context-aware retrieval.
These innovations reduce hallucinations, improve reasoning depth, and make RAG adaptive, not just reactive.
⚡️ Final Thoughts
As we step into an era where LLMs don’t just generate but understand through retrieval, one thing becomes clear : RAG isn’t just a technical upgrade; it’s a shift in how AI connects with human knowledge.
It bridges the gap between memorisation and comprehension, between data and decision-making.
The next generation of systems from research copilots to legal assistants will not rely solely on what they were trained on, but on what they can access in real-time.
That’s where the true intelligence begins: when AI can reason with context rather than hallucinate without it.
💡 Tip:
Visit AI Buddy to explore how everyday businesses are already using AI to their advantage in automating work, improving decisions, and saving hours; all without needing to be tech experts.
Because the future of AI isn’t about coding; it’s about understanding how to make it work for you.